Problem
It's the time of year where I normally have to start doing taxes, not for myself but for my parents. Mum works at various fruit picking / packing places in Hawkes Bay throughout the year, so that means there are all sorts of Payslips from different employers for the last financial year. Occasionally mum would ask me specific details about her weekly payslips, and that usually means: download a PDF from and email -> open up the PDF -> find what's she asking for -> look at the PDF -> can't find it so ask what mum meant -> find the answer -> explain it to her.
Solution & Goal
The usual format, challenge: create a Generative AI conversational chatbot to enable mum to ask in her natural language specific details of her Payslips without me
And the goal: outsource the work to AI = more time to play. 🙂
Success Criterias
- Automatically extract details from Payslips - I've only tested it on Payslips from Rockit Apple.
- Enable mum to ask in Cantonese details of Payslips
- Retrieve data from an Athena Table where the Payslip detail will be stored after they are extract from the PDFs
- Create a Chatbot to receive questions in Cantonese around the user's Payslips stored in the Athena Table, and generate a response back to the user in Cantonese
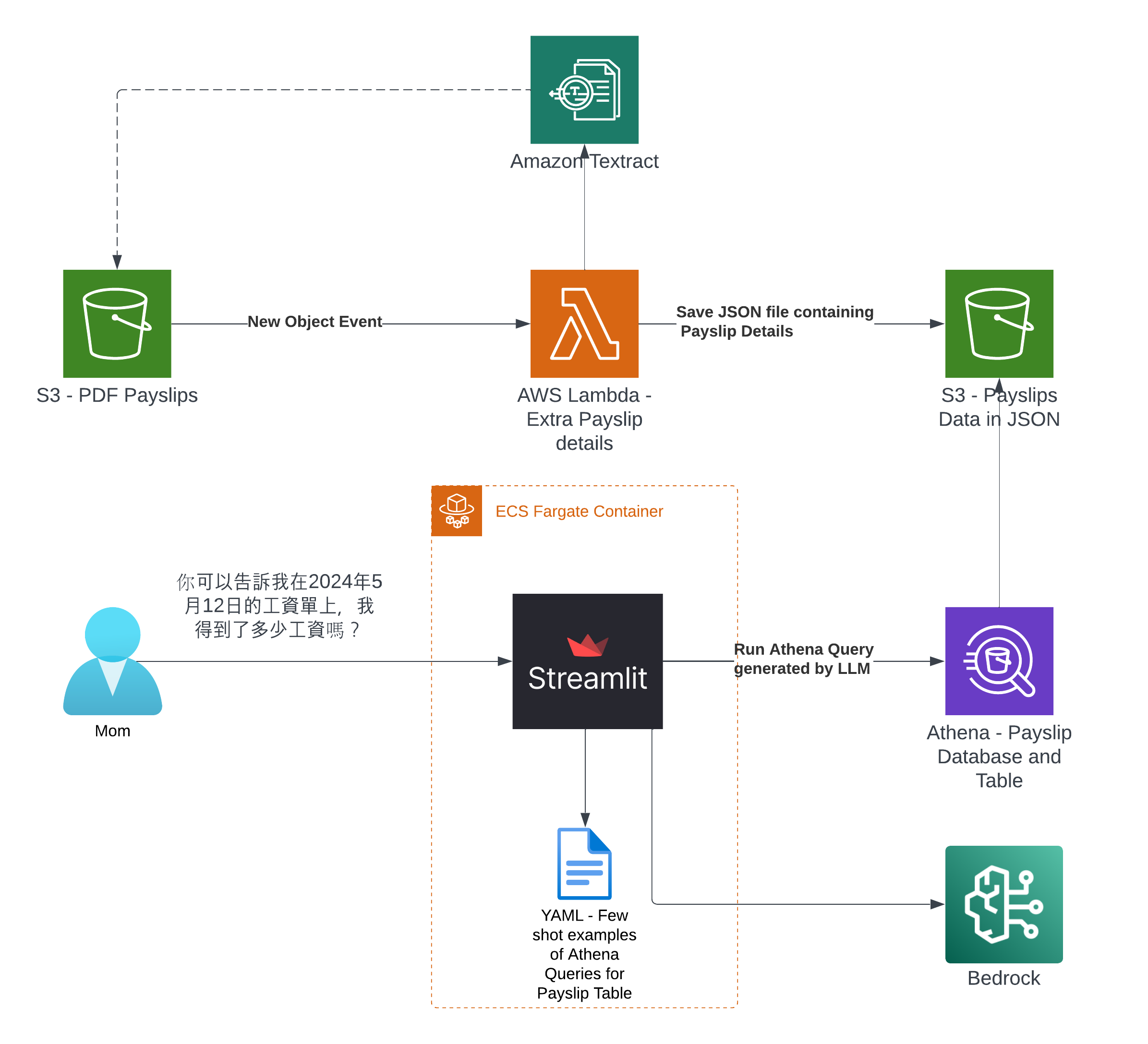
So what's the Architecture?
Note
I've only tried it for Payslips generated by this employer: Rockit Apple
Deploy it for yourself to try out
Prerequisites
- Python 3.12 installed - the only version I've validated
- Pip installed
- Node.js and npm Installed
- CDK installed - using
npm install -g aws-cdk - AWS CLI Profile configured
-
Bedrock Models enabled - specifically
amazon.titan-text-express-v1Deployment CLI Commands
- Open up a terminal
-
And run the following commands
git clone git@github.com:chiwaichan/rockitapple-payslip-analyzer-with-genai-chatbot-using-bedrock-streamlit.git cd rockitapple-payslip-analyzer-with-genai-chatbot-using-bedrock-streamlit python3 -m venv venv source venv/bin/activate pip install -r requirements.txt cdk deploy
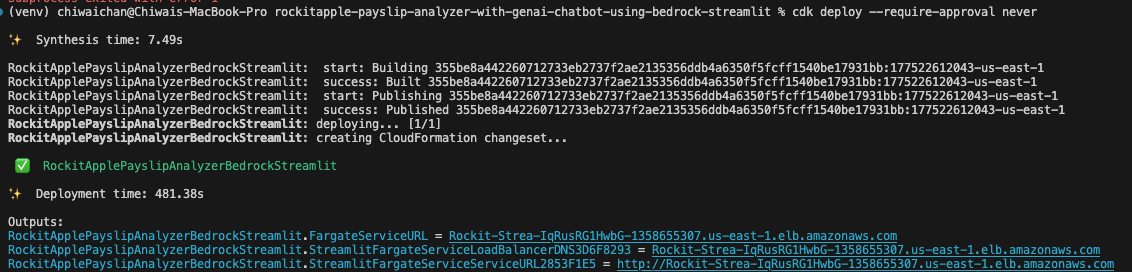
If all goes well
You should see this as a result of calling the cdk deploy
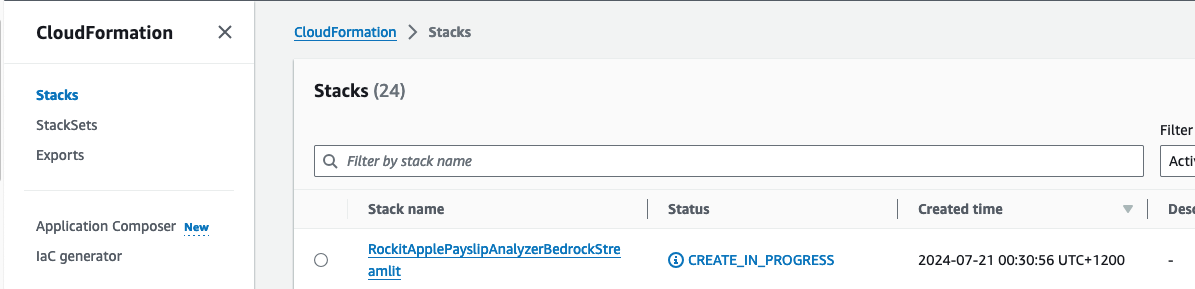
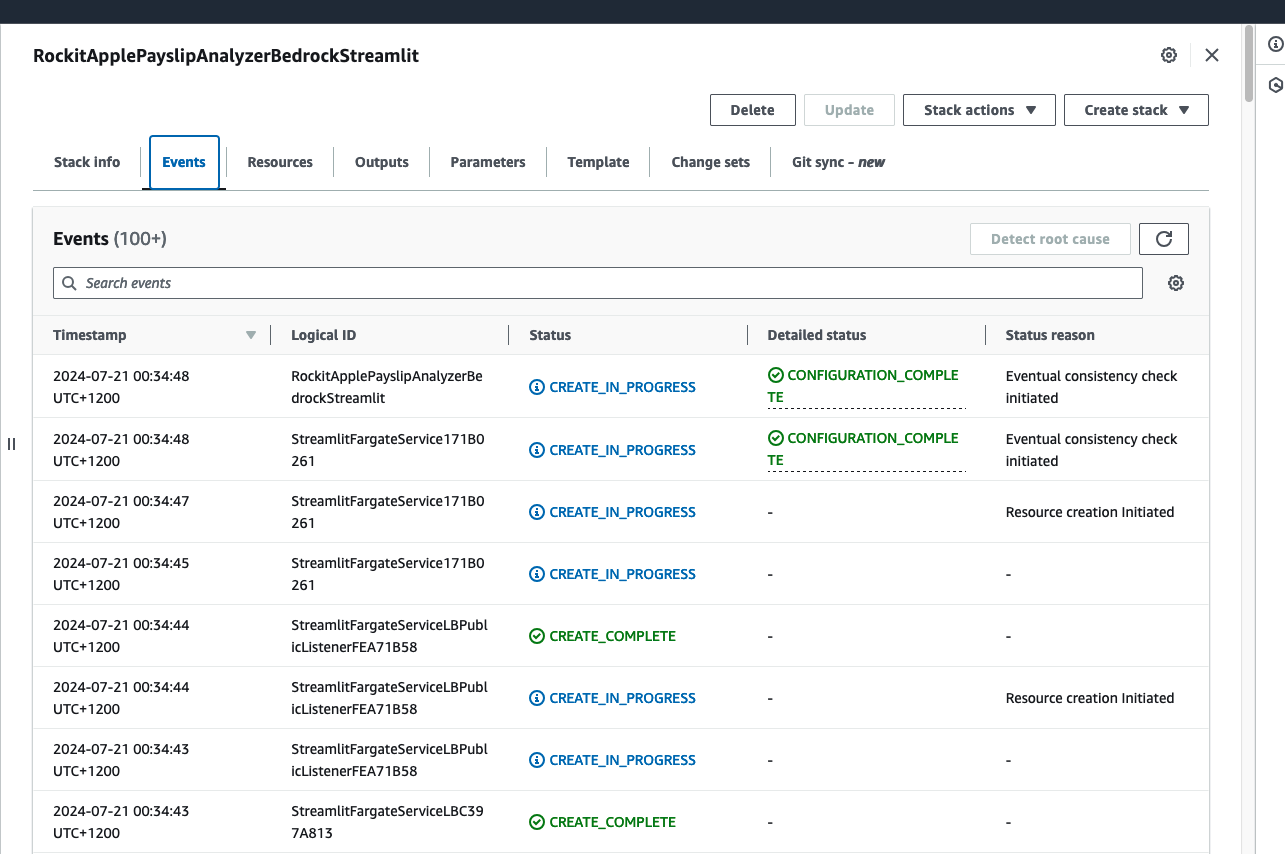
Check that the CloudFormation Stack is being created in the AWS Console
Click on it to see the Events, Resources and Output for the Stack
Find the link to the S3 Bucket to upload Payslip PDFs into, in the Stack's Resources, find the S3 Bucket with a with a Logical ID that starts with "sourcepayslips" and click on its Physical ID link.
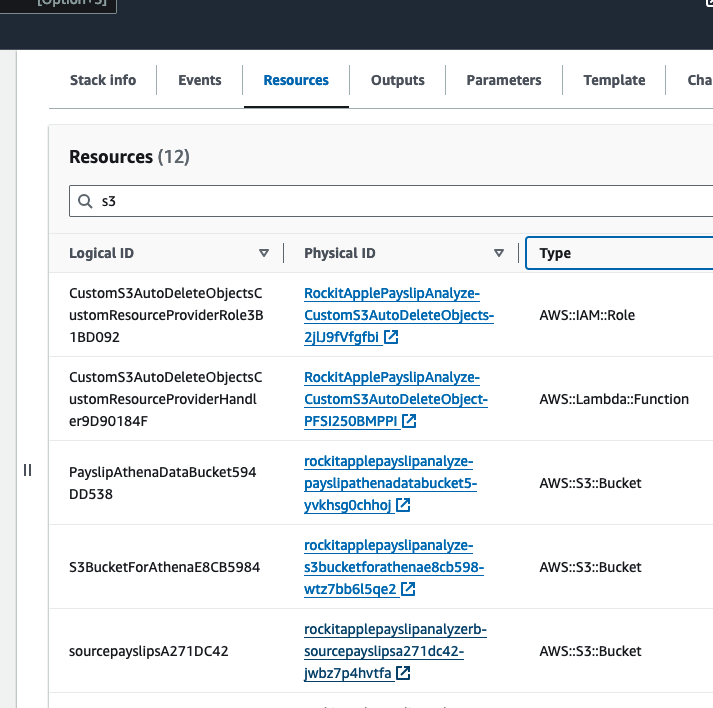
Upload your PDF Payslips into here
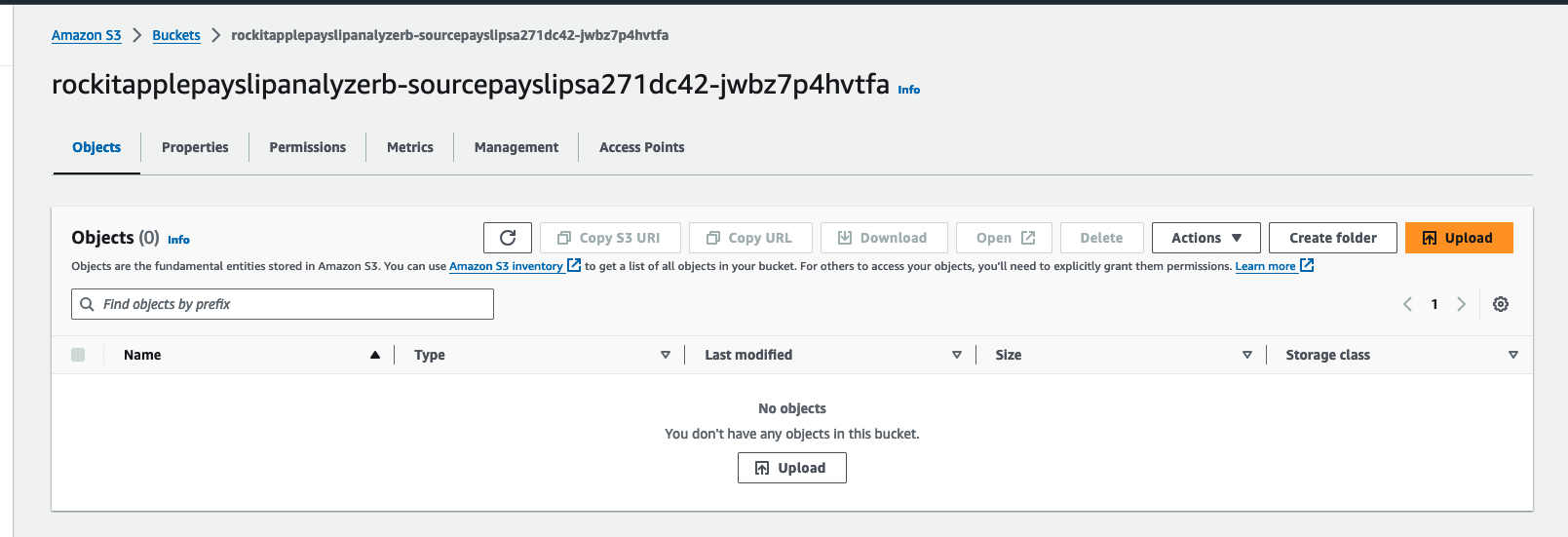
Find the link to the S3 Bucket where the extracted Data will be stored into for the Athena Table, in the Stack's Resources, find the S3 Bucket with a with a Logical ID that starts with "PayslipAthenaDataBucket" and click on its Physical ID link.
There you can find a JSON file, it should take about a few minutes to appear after you upload the PDF.
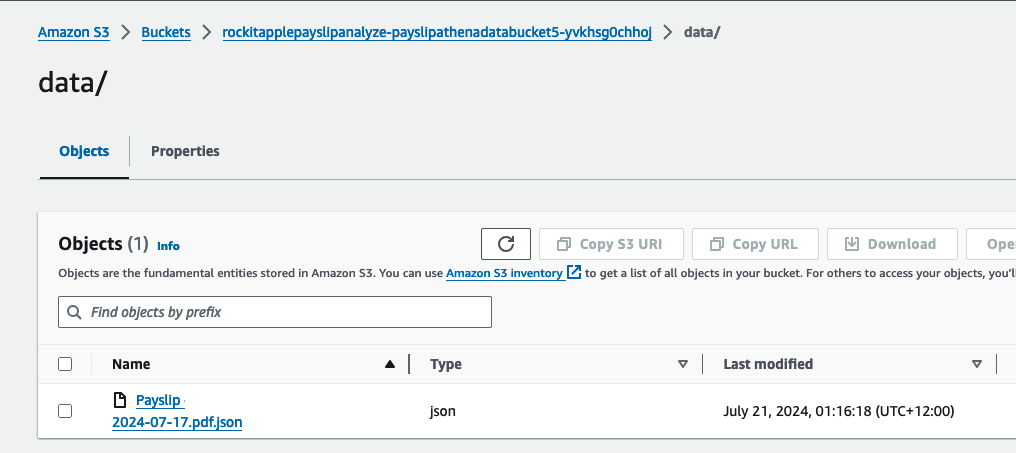
It was created by the Lambda shown in the architecture diagram we saw earlier, it uses Amazon Textract to extract the data from each Payslip using OCR, using the Queries based feature to extract the Text from a PDF by enabling us to use queries in natural language to configure what we want to extract out from a PDF.
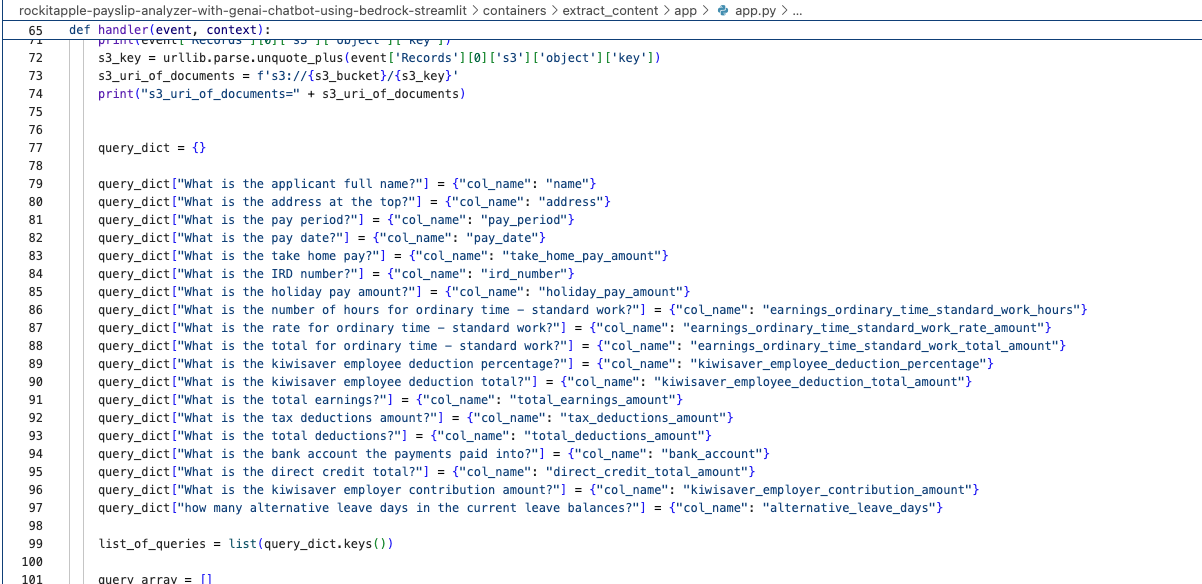
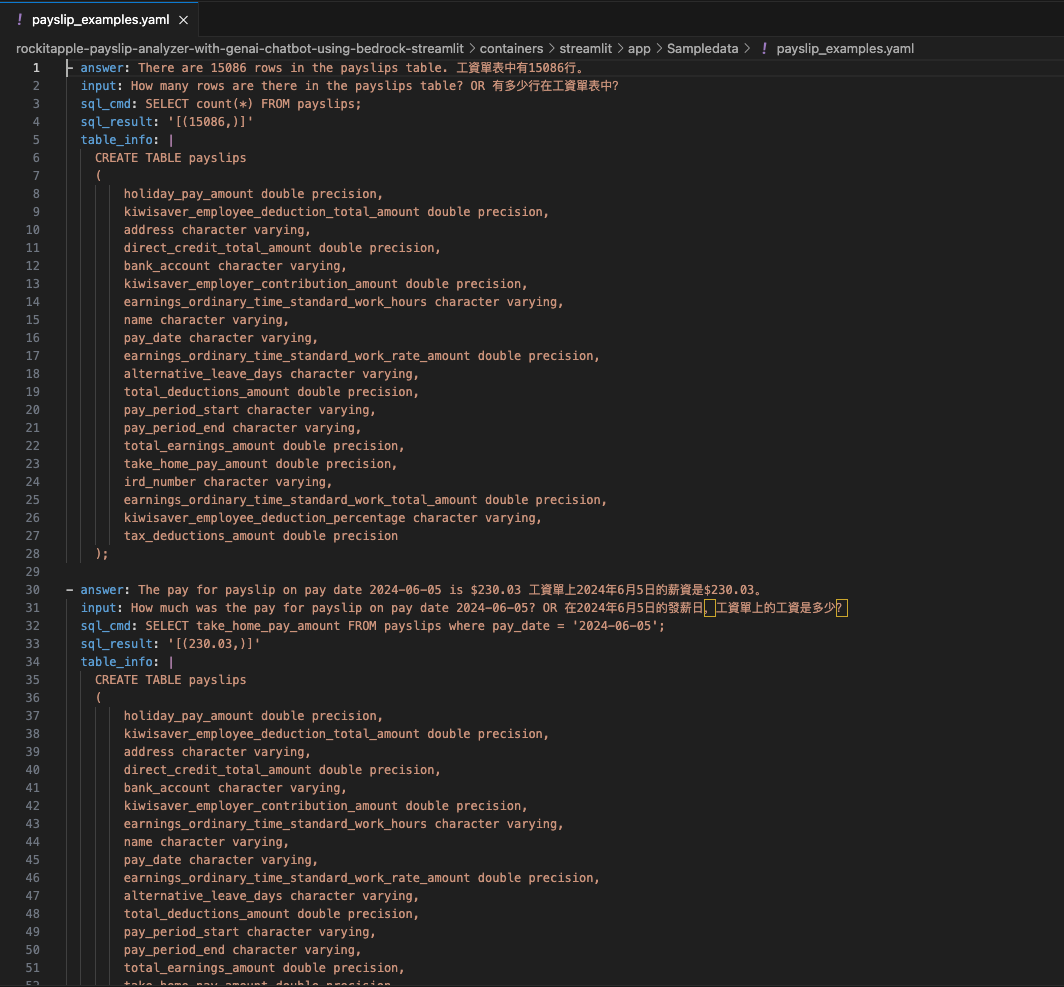
Find the "app.py" file shown in the folder structure in the screenshot below, you can modify the wording of the Questions the Lambda function uses to extract the details from the Payslip, to suit the specific needs based on the wording of your Payslip; the result of each Question extracted is saved to the Athena table using the column name shown next to the Question.
What it looks like in action
Go to the CloudFormation Stack's Outputs to get the URL to open the Streamlit Application's frontend.
Click the value for the Key "StreamlitFargateServiceServiceURL"
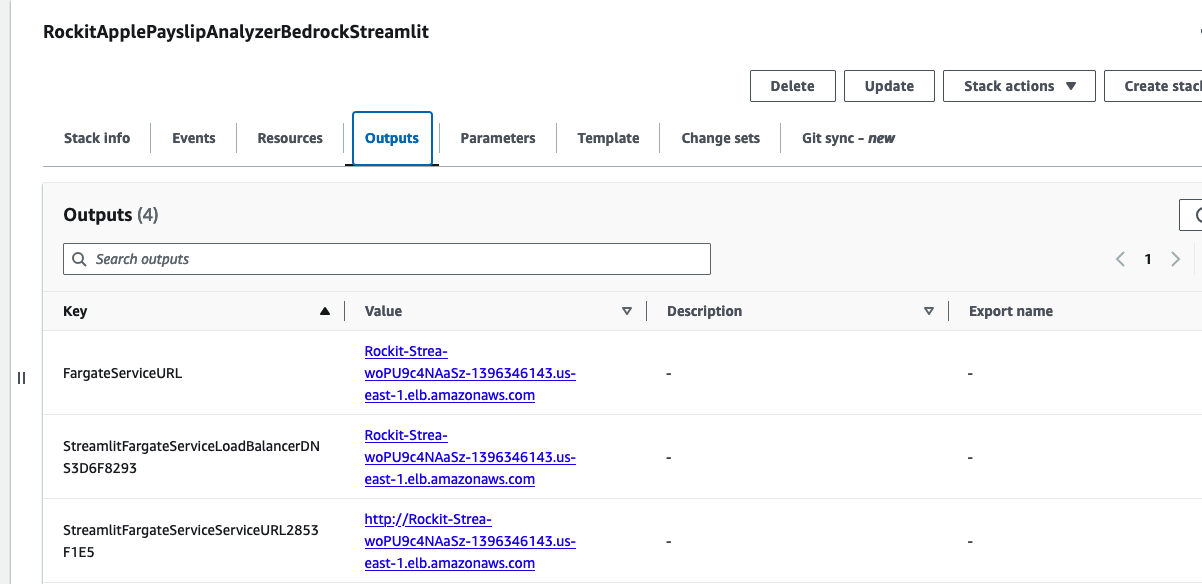
That will take you to a Streamlit App hosted in the Fargate Container shown in the architecture diagram, use "cats" as the username and "cats" as the password - make sure you modify the code with your own authentication/authorisation if you are building on top of this.

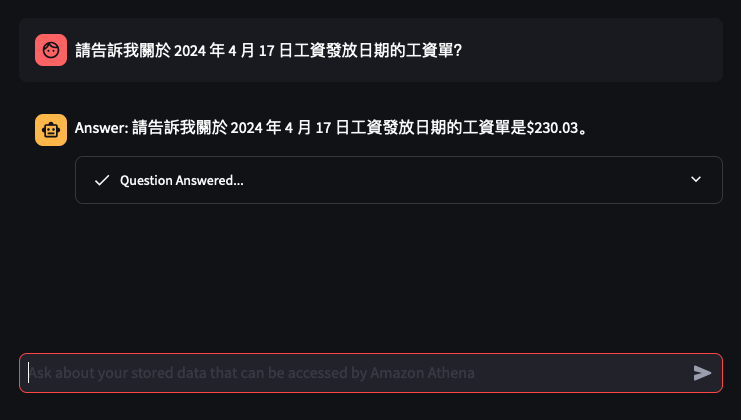
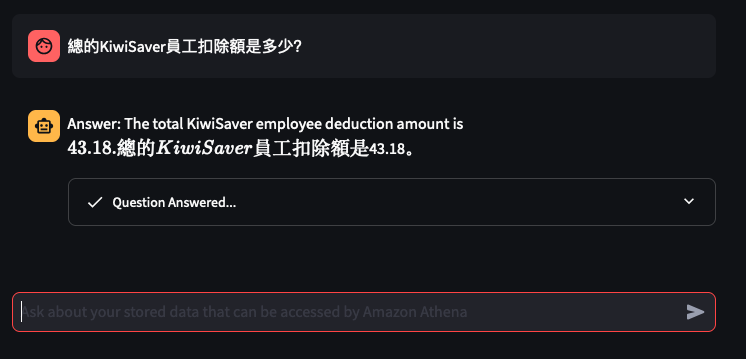
Lets try out some examples
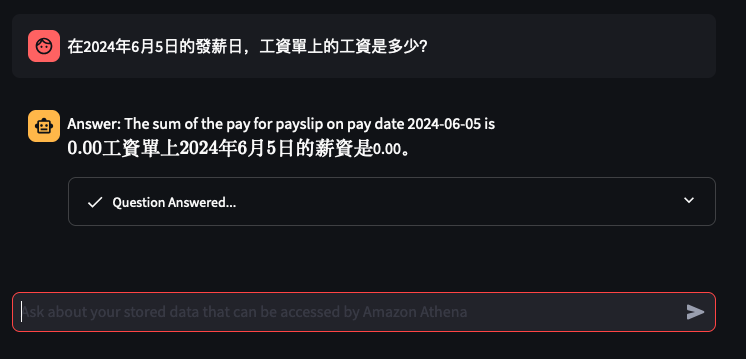
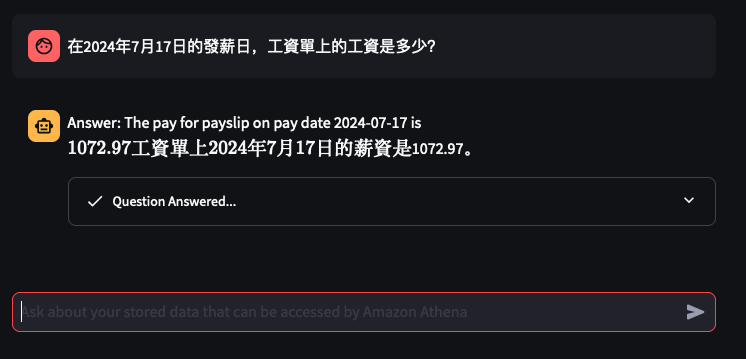
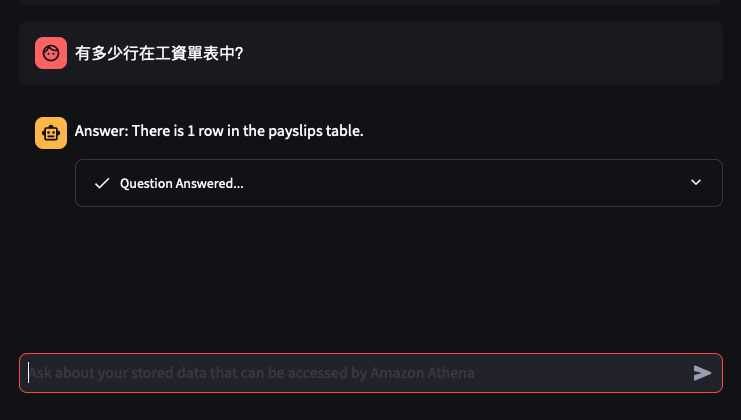
Things don't always go well
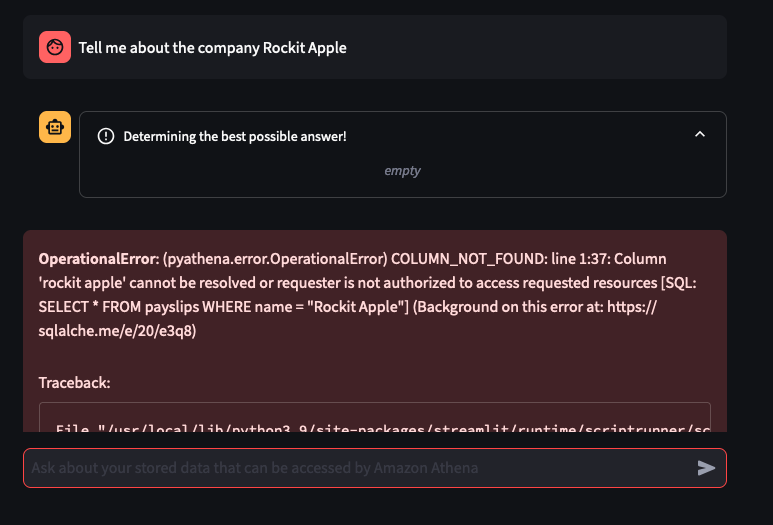
You can tweak the Athena Queries generated by the LLM by providing specific examples tailoured to your Athena Table and its column names and values - known as a Few-Shot Learning. Modify this file to tweak the Queries feed into the Few-shot examples used by Bedrock and the Streamlit app.
Thanks to this repo
I was able to learn and build my first GenAI app: AWS Samples - genai-quickstart-pocs
I based my app on the example for Athena, I wrapped the Streamlit app into a Fargate Container and added Textract to extract Payslips details from PDFs and this app was the output of that.
What's Next
Mum is going to test this app over the next few weeks